
You shipped. The chatbot or voicebot is live. Customers are talking to it every day.
It is automation time.
This is the moment most teams relax on testing. They should be doing the opposite.
When your bot was in development, a failure affected a demo. Now it affects real customers. Your knowledge base will be updated. Your prompts will be tweaked. At some point the LLM provider will release a new model version. Each of these changes can silently degrade performance in ways your existing checks will not catch.
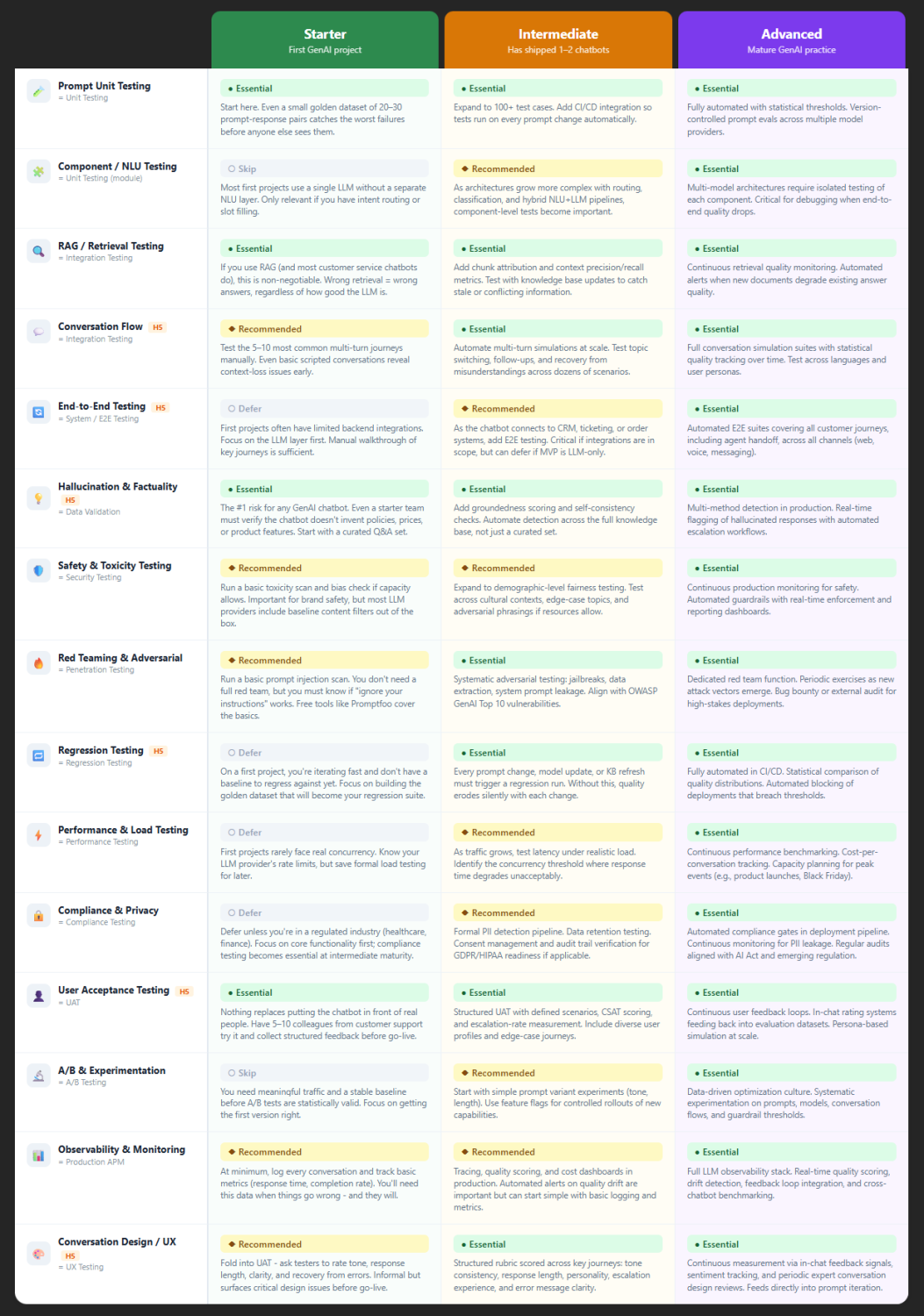
If you built the four foundational tests from Post 2, you have a starting point. Now it is time to build on them. At this stage - the Intermediate level - we find that eight tests need to be running, and four of those should be new additions to your practice.
What Changes at This Stage
When you had one chatbot or voicebot in staging, testing was about catching obvious failures before launch. Now you have something more complex to protect.
You have a baseline. Real conversations are happening. You know roughly what works and what does not. You may have already caught a few surprises in production. That experience changes the way you do testing.
The risks at this stage are less about catastrophic failures and more about slow drift. A prompt that worked well in month one may perform noticeably worse in month three, after a model update, a knowledge base expansion, or a series of small prompt edits that accumulated over time. Without the right tests, you will not see that drift until a customer or a manager notices it.
The four tests below are the ones we see become essential once a team has a live system and real traffic to protect.
Test 5: Regression Testing
Regression testing checks whether a change to your system has broken something that previously worked. In traditional software, this is standard practice. In GenAI, some teams skip it because they have not built a baseline yet.
Once you are live, skipping regression testing is no longer defensible. Every prompt change, every knowledge base update, and every model version swap is a potential regression event. Without this test running, you have no systematic way to know if quality improved or declined after a change.
To set this up, take the golden dataset you built during development and run it against the current system after every significant change. Compare results to the previous run. Flag cases where answers changed and review whether the change was an improvement or a regression.
The next level is to run regression on multi-turn conversations. This is the only way to know - and prove - that your next delivery is as good as, if not better than, the previous one.
What good looks like: before any major change goes live, you run the dataset and review the differences. Surprises do not reach production.

Test 6: Conversation Flow Testing
Prompt unit tests check single-turn inputs. Conversation flow testing checks what happens across multiple turns. It is the difference between testing whether the bot can answer a question and testing whether it can handle a full customer journey.
Multi-turn conversations surface a specific class of failure. The bot may answer each individual question correctly but lose track of context between them. A customer who says “I want to return it” two messages after discussing a specific order should not be asked what they are referring to. Topic switches, follow-up questions, and interruptions are all sources of failure that single-turn testing will not catch.
Voice bots have additional challenges here. Callers do not always follow a logical sequence. They interrupt. They go back to earlier topics. They give partial information and expect the bot to remember it.
Start by mapping out your five to ten most common customer journeys, with a target of fifteen to thirty over time. Write scenario test conversations for each one. Run them - even manually if you have to - and record where the bot fails to maintain context, handles transitions badly, or gives inconsistent answers within the same session.
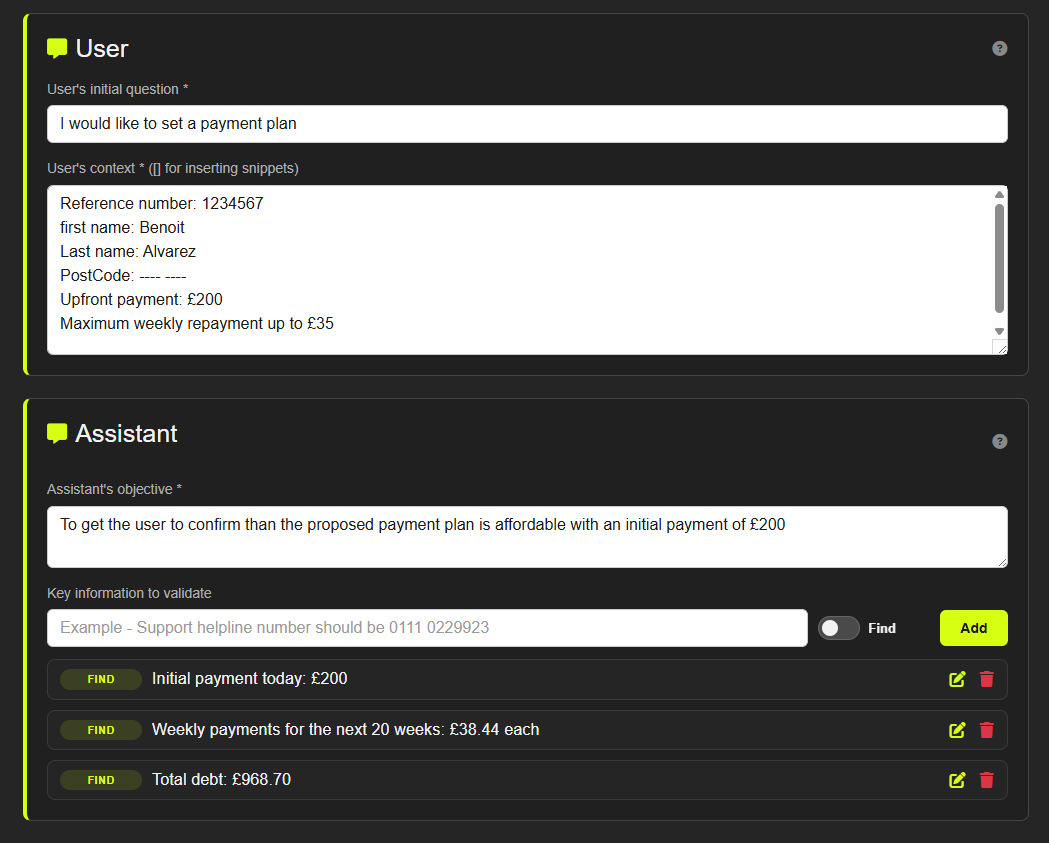
Then automate it for scale. For each scenario, define:
- User goal: what the user is trying to achieve (e.g. increase the overdraft on their joint account)
- User-specific context: relevant attributes (e.g. premier client, co-signatory on the account, resident outside the country)
- Chatbot objective: the correct outcome (e.g. inform the user that a co-signature is required because they reside outside the UK)
What good looks like: your most important multi-turn journeys are tested before each major release. Context handling issues are found in testing, not by customers.
Test 7: Red Teaming and Adversarial Testing
You ran a basic adversarial check before launch. That was enough to catch the most obvious risks. At this stage, a more systematic approach is needed.
Red teaming means deliberately trying to make your bot behave badly. This includes prompt injection attacks, attempts to extract the system prompt, jailbreaks, and manipulative phrasings designed to get the bot to say something it should not. As bots handle more sensitive topics and more complex integrations, the attack surface grows.
The OWASP GenAI Top 10 is a useful reference here. It documents the most common vulnerability classes for LLM applications and is worth working through systematically at this stage.
This does not require a dedicated security team. It requires someone willing to spend a few hours trying to break the bot in structured ways, documenting what they find, and fixing the issues that matter - or automating it.
What good looks like: you have tested against the most common attack types and addressed the ones that pose real risk to your customers or your business. You revisit this whenever a significant new capability is added.

Test 8: Conversation Design and UX Evaluation
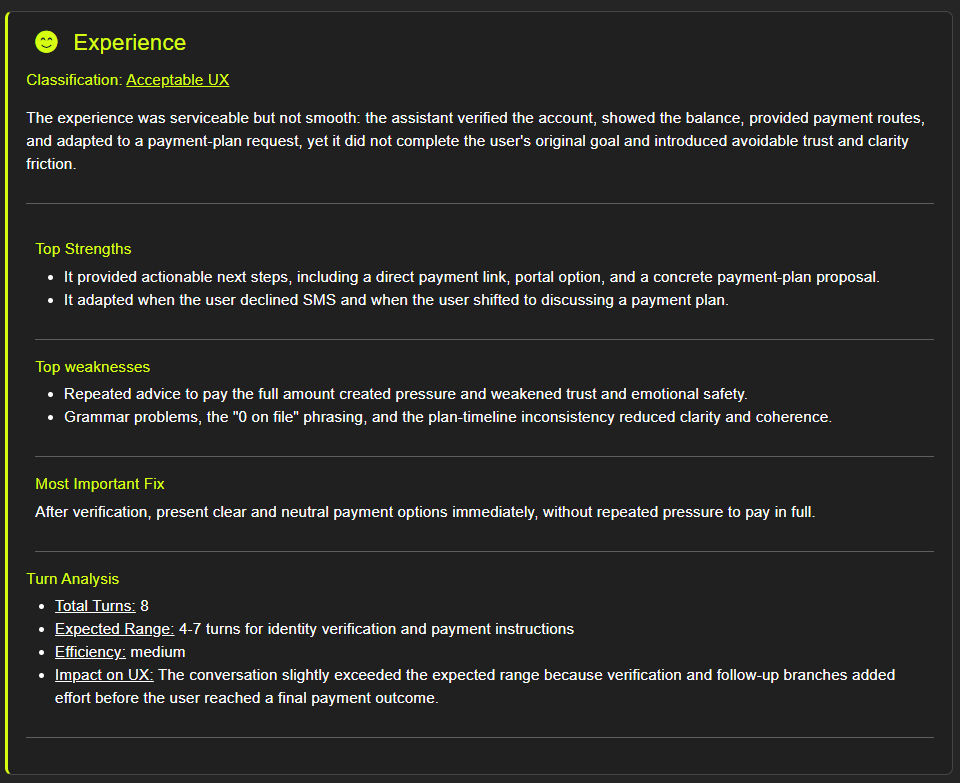
This test is easy to underestimate. It is not about whether the bot gives correct answers. It is about whether the experience of talking to it is actually good.
Common issues at this stage include responses that are technically accurate but far too long, a tone that does not match your brand, poor handling of requests the bot cannot fulfil, and error messages that confuse rather than help. In voice, add unnatural phrasing, awkward pacing, and a lack of acknowledgment when the user has to repeat themselves.
These issues rarely show up in automated tests. They require human judgment. Build a simple evaluation rubric: tone consistency, response length, clarity, escalation quality, and error handling. Have someone work through the key journeys and score them. This does not take long and consistently surfaces meaningful improvements.
Technical accuracy is table stakes. The quality of the experience is what determines whether customers trust the bot and keep using it.
What good looks like: your main journeys have been evaluated against a written rubric. Design issues are tracked and addressed systematically rather than when someone happens to notice them.
What to Start Considering
Remember: all of the above have to be tested for consistency across multiple runs. Never rely on a single test result. This is also why automation is key.
Beyond the four new essential tests, two areas are worth beginning to think about at this stage, even if you do not yet have full programmes in place.
End-to-end testing becomes relevant as your bot connects to more backend systems. If the bot can look up an order, initiate a return, or check an account balance, you need to know whether those integrations work correctly end to end - not just whether the conversational layer is functioning.
Compliance and privacy testing matters more as the bot handles more sensitive data. If you operate in a regulated industry or handle personal data subject to GDPR or similar regulations, begin mapping out what testing is required. The compliance work is easier to build gradually than to retrofit under pressure.
Performance and load testing is worth scoping if your traffic is growing. Know your LLM provider’s rate limits and understand at what scale latency becomes a customer experience problem.
Your Testing Checklist at This Stage
You should now have the four starter tests from Post 2 running, plus the following:
- Regression testing against your golden dataset, run before every significant change
- Conversation flow testing covering your top 15–30 customer journeys
- Systematic red teaming against common attack types, repeated after major changes
- Conversation design evaluation using a written rubric across key journeys
Eight tests in total. The start of real automation and scaling. Not a perfect setup - but a real programme that protects what you have built and gives you a fighting chance of catching problems before customers do.
Post 4 covers what a mature GenAI testing practice looks like: teams running multiple bots across channels, mostly automated, with an honest look at where even advanced teams still struggle.