
By the time a team reaches this stage, they are typically running multiple bots across channels. Chat and voice. Internal tools and customer-facing products. Different business units with different requirements. The problems change.
At the starter and intermediate stages, the main challenge is catching failures before customers find them. At the advanced stage, that challenge does not go away. But new ones emerge. Quality needs to be measured continuously, not just before releases. Testing needs to run without human intervention. Decisions about prompt changes, model upgrades, and new features need to be backed by data.
This post covers the seven tests that become essential at the advanced stage - the ones not yet running at intermediate. Together with the eight from the earlier posts, they complete the full set of 15.
We will also be direct about something: in our experience, there are no advanced teams that have all of this running perfectly. The field is too young. The tooling is still catching up. What we describe here is a direction, not a finished state.
The 7 Tests That Complete the Stack
Three of these are non-negotiable at this stage:
- End-to-End Testing
- Observability and Production Monitoring
- Load Testing
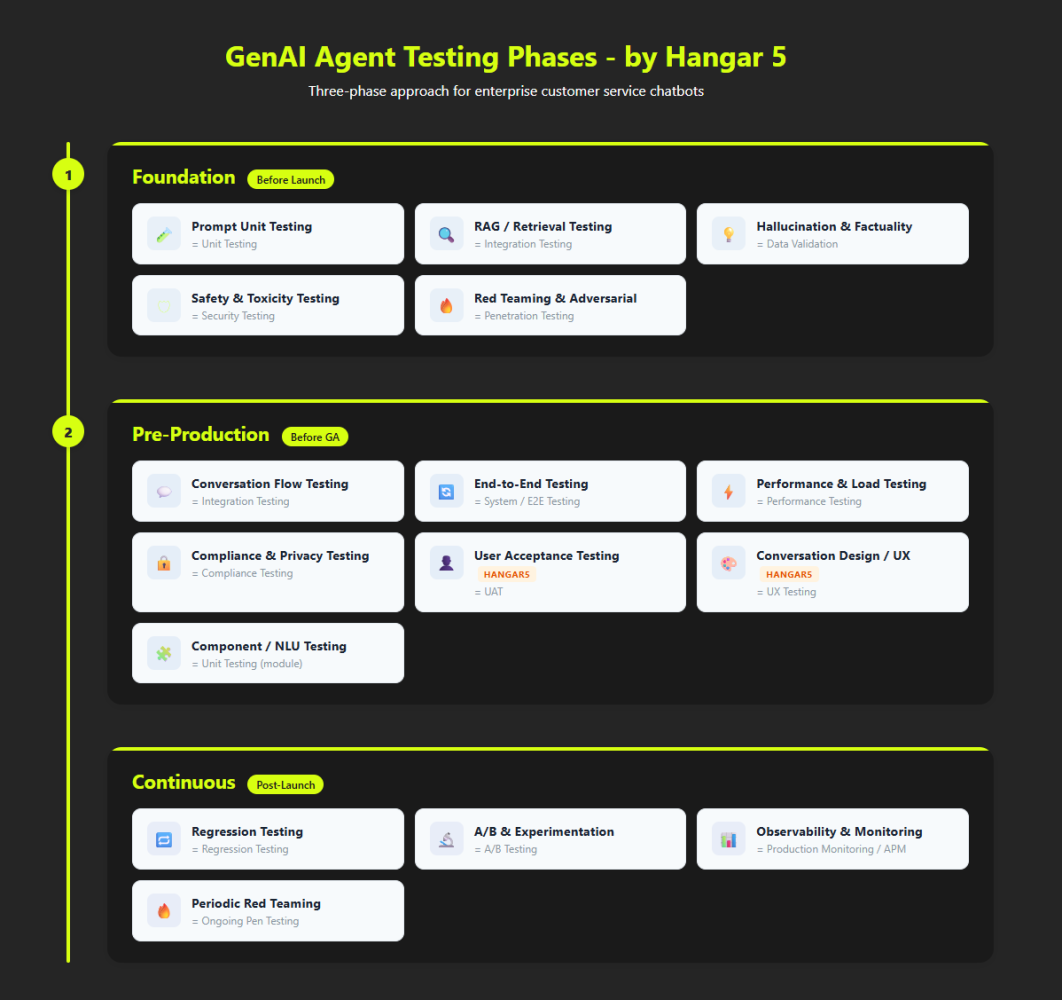
Component Testing
As bot architectures become more complex, the conversational layer often includes multiple components: orchestration layers that coordinate between models, amplification of context from APIs, task execution. Component testing isolates each of these and verifies they work correctly on their own, before testing the full system together.
This becomes critical when end-to-end quality drops and you need to know where the problem is. Without component-level tests, debugging a multi-model system is slow and often guesswork.
Start by mapping your architecture. Identify every component that has a distinct function and can fail independently. Write isolated tests for each one.
End-to-End Testing
End-to-end testing verifies that a complete customer journey works correctly across every system the bot touches. This includes backend integrations such as CRM lookups, order management, ticketing systems, and agent handoff platforms.
At earlier stages, this could be deferred because the bot had limited integrations. At the advanced stage, most bots are deeply connected to backend systems. A failure anywhere in that chain creates a bad customer experience. End-to-end tests need to cover every integration and every complete journey, including the transitions between systems.
Voice bots require particular attention here. A call that involves an account lookup, a transaction, and a handoff to a live agent is a multi-system journey with many potential failure points. Test it end to end and test it regularly.
Note: for voice bots, many teams bypass the voice layer and focus on text-to-text testing. This has the advantage of reducing the cost of testing dramatically, while still covering the core logic.
Safety and Toxicity Testing
Most LLM providers include increasingly advanced content filters. At earlier stages, relying on those is acceptable. At the advanced stage, you may need to go further - and most of this will need to be built in house, as no off-the-shelf solution currently goes beyond provider-level filters.
Advanced teams run continuous safety monitoring in production. They test across demographic groups to catch differential behaviour - such as a bot that responds differently to the same request depending on language or phrasing. They test across cultural contexts, edge-case topics, and adversarial phrasings. And they have automated guardrails that flag concerning outputs in real time, not just during pre-launch reviews.
For voice bots, this includes testing how the bot handles distressed or vulnerable callers - a scenario that chat bots can navigate more easily with tone softeners and written resources.
Performance and Load Testing
Once you have real traffic and business-critical journeys, you need to know what your system does under pressure. This means testing latency under realistic concurrent load, identifying the threshold at which response time degrades to an unacceptable level, and understanding the cost implications of scale.
LLM inference is expensive. A bot that performs fine at a hundred concurrent sessions may behave very differently at a thousand. Cost per conversation is also a metric worth tracking. Bots that were economical at launch can become costly as usage grows or as prompt complexity increases.
For voice bots, latency matters more than in chat. Users are waiting in real time. A response that takes four seconds feels noticeably slow in a voice interaction in a way it would not in a chat window.
Compliance and Privacy Testing
At the advanced stage, compliance is not optional in most enterprise contexts. GDPR, the EU AI Act, HIPAA for healthcare, and sector-specific regulations all create requirements that need to be verified through testing.
This includes PII detection to ensure the bot does not echo back or store sensitive customer data inappropriately, data retention testing to verify that conversation logs are handled according to policy, and audit trail verification for regulated use cases. It also increasingly includes documentation of how the AI system makes decisions, which is required under some emerging frameworks.
Build compliance testing into your deployment pipeline. Compliance failures discovered in production are significantly more expensive to address than those caught before release.
A/B Testing and Experimentation
Once you have meaningful traffic and a stable baseline, you can run controlled experiments to improve bot performance. This means testing prompt variants, comparing response styles, evaluating the impact of different escalation thresholds, or measuring whether a new conversation flow performs better than the existing one.
A/B testing requires statistical discipline. You need enough traffic for results to be meaningful. You need to measure the right outcomes - which are not always the most obvious ones. Response quality matters, but so do completion rate, escalation rate, customer satisfaction, and for voice, call duration and repeat contact rate.
Start with simple experiments. Two prompt variants on a single journey. One variable at a time. Build the practice before scaling it.
Observability and Production Monitoring
This is the test that ties everything else together. Observability means having continuous visibility into how your bot is performing in production - not just before releases.
A mature observability stack includes:
- Real-time quality scoring of live conversations
- Drift detection to catch gradual degradation before it becomes visible
- Cost dashboards tracking spend per conversation across models and channels
- Automated alerts when key metrics fall below defined thresholds
- Feedback loop integration so that signals from live users flow back into your evaluation datasets
For teams running multiple bots, observability also enables cross-bot benchmarking. Which bots are improving? Which are degrading? Where are the common failure patterns?
Without observability, advanced testing is mostly an illusion. You can run extensive pre-launch checks and still have no idea what is actually happening once the bot is live.
Where Even Advanced Teams Struggle
We see consistent gaps even in the most mature teams.
Voice testing is almost always underdeveloped relative to chat. The tooling is less mature, and voice-specific failure modes - ASR errors, awkward TTS rendering, and recovery from misheard inputs - are rarely covered in standard test suites. If you run voice bots, this is probably a gap worth addressing.
Feedback loops between production and testing datasets are often weak. Live conversations surface new failure modes and new user phrasings every day. Most teams are not systematically capturing these and using them to update their evaluation sets. This means test coverage gradually falls behind real usage patterns.
Red teaming frequency tends to drop off after initial deployment. Attack techniques evolve. New capabilities create new attack surfaces. A red team exercise that was current at launch may miss vulnerabilities that are well-documented six months later.
What a Mature Practice Actually Looks Like
Testing a GenAI bot is not a project with an end date.
It is mostly automated. Testing runs in CI/CD pipelines. A prompt change triggers a regression run automatically. A model version update triggers a full evaluation suite before the change is promoted to production. Deployment can be blocked automatically if quality metrics fall below defined thresholds.
It is monitored continuously. Quality is not a pre-launch check. It is a live metric, measured in production alongside cost, latency, and completion rate.
It improves itself. Feedback from live conversations flows back into evaluation datasets. Tests get better as the system gets better - or as the system reveals new ways it can fail.
And it is honest about what it does not know. The teams doing this best are not the ones claiming their bot is fully tested. They are the ones with the clearest view of where their coverage is incomplete and what they are working on next.
That is a good place to end this series. Not with a finished checklist, but with the idea that testing a GenAI bot is not a project with an end date. It is a practice that matures alongside the system it is built to protect.