78% of enterprises now have generative AI in production. Yet according to MIT, 95% of those implementations fail to meet expectations. The models aren’t the problem. The problem is what happens after the demo: teams ship without knowing whether their AI assistant actually works the way real customers experience it.
Most test what they can, document what they can’t, and hope for the best. That’s not quality assurance. That’s unmanaged risk.
Why traditional QA breaks for LLMs
Traditional testing tools were built on one assumption: the same input produces the same output. Write a test, it passes, ship it. That model works for deterministic software. It breaks completely for LLM-based assistants.
The same question can generate different answers. Conversations span multiple turns, topics, and unexpected tangents. Real users don’t phrase things the way your test cases anticipated; they use slang, change direction mid-sentence, and arrive with context your scripts never considered. An assistant that passes every structured test can still fail catastrophically when an actual customer walks in.
Most teams respond to this by validating a handful of prompts, checking intent recognition in isolation, and relying on deterministic scripts for systems that are fundamentally non-deterministic. When they can’t test something, they document the risk and move on.
In regulated industries such as telecoms, financial services, and healthcare, that documented risk doesn’t stay quiet for long. A single hallucinated response can trigger regulatory review, legal exposure, or a news story. The cost of one incident exceeds significantly the cost of testing properly.
Where conversational AI actually fails
LLM-based assistants don’t fail at understanding intent. They fail inside conversations.
They lose context across turns. A user explains their situation in message one. By message four, the assistant responds as if the conversation never happened. Context decay is invisible when you’re testing single prompts; it only surfaces across full dialogues.
They hallucinate with confidence. The assistant doesn’t hedge or flag uncertainty. It states fabricated information with the same fluency as accurate information. Confident wrongness is far harder to catch than obvious confusion, and far more damaging to trust.
Real users don’t follow scripts. Slang, typos, topic changes, incomplete sentences. Clean test cases don’t reflect real users. Production traffic does.
This is the gap that a score on an isolated prompt can never reveal. The failure is in the conversation, which means the test has to be the conversation.
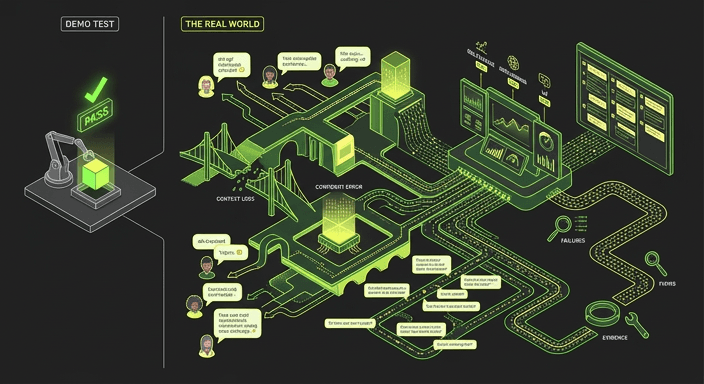
What evidence-based testing looks like
Testing conversational AI properly means running full, end-to-end dialogues at the scale and variety that reflects how real customers actually behave. Not 50 hand-crafted prompts reviewed by a QA team. Thousands of realistic, multi-turn conversations, across different personas, phrasings, topics, and edge cases, scored consistently and reviewed in full.
Three dimensions matter across every conversation:
Relevance: Did the assistant respond to what the user actually asked, across the full dialogue? Not just the first message.
Grounding: Were responses consistently rooted in approved knowledge, or did the assistant drift into fabrication?
User experience: Did the conversation flow naturally, or would a real customer abandon and escalate?
A score per conversation gives you a defensible, reportable quality signal. But a score alone doesn’t always tell you what to fix. Seeing a failure unfold, turn by turn, exactly as a customer would experience it, is what drives action.
Shipping with evidence, not hope
The teams that will get durable value from enterprise AI are not the ones that shipped fastest. They’re the ones that could prove, before go-live, that their assistant behaved reliably across the full range of real-world interactions.
That proof doesn’t come from manual testing at 50–100 interactions per day. It doesn’t come from rule-based scripts that break every time the model updates. And it doesn’t come from checking intent recognition in isolation and calling it done.
It comes from running the conversations. All of them. And seeing exactly what happens.