Most teams building AI assistants start by writing a set of test prompts. They send a question, check the answer, and if it looks reasonable, they mark the test as passed. It’s a natural starting point and it’s almost completely inadequate for the systems they’re building.
The reason is simple: real users don’t have single-turn conversations. They ask follow-up questions. They change topic mid-way through. They refer back to something said three messages ago. They phrase things in ways your test cases never anticipated.
The problem with prompt-level testing
Traditional software testing assumes deterministic behaviour. The same input always produces the same output. You write a test, it passes, you ship. That model works well for APIs, rule-based systems, and most traditional applications.
LLM-based assistants break that assumption in two ways:
- Non-determinism: The same question can produce meaningfully different answers on different runs. A test that passes today may fail tomorrow with no code changes.
- State across turns: The quality of a response often depends entirely on what happened earlier in the conversation. An assistant that answers question one perfectly can still fail your user badly on question four.
Testing at the prompt level means you’re validating neither of those dimensions. You’re measuring a static snapshot of a dynamic, stateful system.
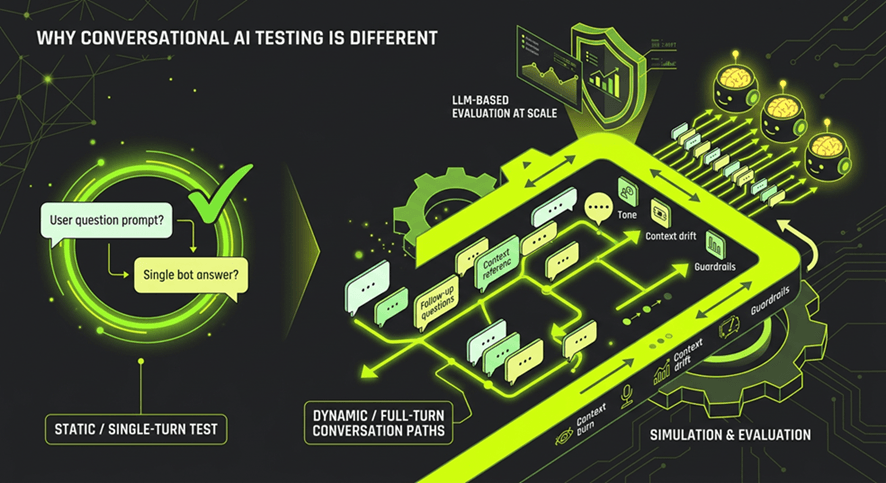
What end-to-end testing actually tests
When you test a full conversation - from first message to resolution - you start seeing failure modes that prompt-level tests can’t surface:
- Context decay: Does the assistant remember what was established in turn one when answering in turn six?
- Hallucination under pressure: Does confidence in the answer hold up as the conversation gets more specific and complex?
- Persona drift: Does the assistant maintain its tone, scope, and guardrails across a full dialogue, or does it wander?
- Edge-case paths: What happens when a user follows an unexpected but realistic path through the conversation?
None of these are visible in a prompt-response pair. They only emerge across the full arc of a conversation.
Scale is the other dimension
Even if you decide to test full conversations, doing it manually doesn’t scale. A single conversational AI assistant might support thousands of different user journeys. Manual testers can explore a handful of paths before a release. That leaves the overwhelming majority of real-world usage untested.
“We tested what we could” is not an assurance model. It’s a statement about the limits of your process, and in regulated industries, those limits become liabilities.
The solution is to simulate realistic conversations at scale; generating synthetic users that behave like real people, across the full range of conversation paths your assistant might encounter in production.
Evaluating the output
Testing at scale creates a new problem: how do you evaluate thousands of dialogues? You can’t read them all. And traditional pass/fail assertions don’t work well for natural language output.
This is where LLM-based evaluation becomes valuable. Using a separate model as an evaluator, one that scores each turn against criteria like relevance, groundedness, and persona consistency, it lets you get signal across large volumes of conversations without manual review.
The key is that the evaluation must happen at the conversation level, not the turn level. A response that looks fine in isolation might be the point where context was lost. You need the full dialogue to make that judgment.
What this means in practice
Shifting from prompt-level to conversation-level testing requires a change in tooling, process, and mindset. But the change in coverage is substantial. Teams that make the shift consistently find failure modes they didn’t know existed and can fix them before a real user encounters them.
That’s what testing conversational AI actually looks like. Not checking individual answers, but proving that the full experience holds up under realistic, varied, end-to-end use.